앞서했던 STFT에 Mel_Frequency Filter Bank를 적용시키는 부분입니다.
Log Operation 까지 적용했습니다.
%% Adapt mel_filterbank
filter_demension=30;
MFB=melfilterbank(filter_demension, N, FS);
%Frequency to Mel-frequency
%주파수->멜주파수
Aspec=MFB*PSPEC;%Aspec:Audio Spectrogram
[mel_x,mel_y]=meshgrid(time,[1:filter_demension]);
figure;
mesh(mel_x,mel_y,Aspec);
%% Get Log Operation
LAspec=log(Aspec);
figure;
mesh(mel_x,mel_y,LAspec);
필터의 갯수를 30개로 하였습니다.
MFB는 멜 필터뱅크로 인수는 (필터갯수, NFFT(주파수 레졸루션, 2^9), FS(주파수 16000Hz))
Aspec는 오디오스펙트로그램으로 앞서 구한 MFB에 파워스펙트로그램인 PSPEC를 곱해줍니다.

AudioSpectrogram
LAspec는 로그를 적용한 오디오스펙트로그램입니다.

Loged AudioSpectrogram
앞서 spectrogram함수로 구한 스펙트로그램과 비슷하다는걸 알 수 있습니다. 정보의 용량이 대폭 줄었죠.

spectrogram
오늘 다루려고 하는것은 위의 melfilterbank(filter_demension, N, FS) 함수입니다.
사실 이 부분을 제대로 이해하지 못해서, 다른 matlab코드를 분석하면서 공부했죠...
함수 내용입니다.
-------------------------------------------------------------------------------
function m = melfilterbank(p, n, fs)
% The function computed the mel filter banks for robust speaker recognition
% The filter spectrum is such that the passband area remains the same yet
% the pasband frequencies decrease and the power increases, to emphasis the
% higher frequency components
% p number of filters in filterbank
% n length of fft
% fs sample rate in Hz
f0 = 700/fs;
fn2 = floor(n/2); %16000/2=8000
lr = log(1 + 0.5/f0) / (p+1); %p+1만큼 등간격 등분
% convert to fft bin numbers with 0 for DC term
bl = n * (f0 * (exp([0 1 p p+1] * lr) - 1));
b1 = floor(bl(1)) + 1;
b2 = ceil(bl(2));
b3 = floor(bl(3));
b4 = min(fn2, ceil(bl(4))) - 1;
pf = log(1 + (b1:b4)/n/f0) / lr;
fp = floor(pf);
pm = pf - fp;
r = [fp(b2:b4) 1+fp(1:b3)];
c = [b2:b4 1:b3] + 1;
v = [1-pm(b2:b4) pm(1:b3)];
m= sparse(r,c, v, p, 1+fn2);
figure;
hold on
for num=1:p
plot(m(num,:));
end
-------------------------------------------------------------------------------
사실 위 함수 말고도 다른 함수가 여럿 있었습니다만 이 함수가 제일 메모리를 적게 먹더군요.
그 이유가 바로 sparse함수 때문이었습니다.
매트릭스를 보면 0이 많은 경우가 많습니다. 사실 이런 데이터는 굳이 표현해 줄 필요가 없습니다.
예를들어 290*380의 매트릭스에서 60퍼센트 정도의 데이터가 0이면 이걸 다 표현해주면 290*380*0.6이라는 엄청난 메모리 낭비가 있습니다. 여기서 sparse를 이용해서 유효한 데이터의 값과 좌표데이터만 표현해 주자는 것이죠.
안드로이드 앱등의 플랫폼에 옮긴다고 할 때 메모리 문제는 굉장히 예민하게 다루어집니다. 이런 부분에서 세심한 배려가 제품의 가치를 높이는 것이겠죠.
그럼 함수 설명을 시작하겠습니다. 하나하나 짚어가면서 진행합니다.
일단 멜 필터뱅크 구축에 사용되는 함수는 두가지 입니다.


M(f)는 주파수를 Mel주파수로 바꿉니다.
M^(-1)(m)은 Mel주파수를 주파수로 바꿔줍니다.
여기서 주의, 1125라는 값을 보죠. M^(-1)(m)의 m에 M(f)를 대입시키면 1125/1125가 되어 f가 됩니다.
위 함수에서 1125값이 보이지 않는것은 이것 때문입니다.
음성 분석을 할 때, 주어지는 FS의 절반에 해당하는 주파수의 정보까지 얻을 수 있습니다.
FS=16000, 따라서 8000Hz까지 분석하게 되죠. 앞서 STFT에서 8000Hz까지 분석하는것도 같은 이유입니다.
lr 에서 /(p+1)을 제외하고 봅시다.
lr = log(1 + 0.5/f0);
f0 = 700/fs; 까지 대입시켜 보면
lr = log(1+0.5*fs/700) 으로 (1)식에서 1125를 제외한 식이 됩니다.
여기서 /(p+1)을 하는 이유는 (p+1)등분 하기 위해서이죠. 30개의 필터를 만든다고 하면 p+1=31로 나눕니다.
앞서 영문자료 보면 10개 필터를 만들경우 포인트를 +2한 12포인터를 잡습니다. 일단 이렇게 알아둡시다.
bl을 분석해 봅시다.
bl = n * (f0 * (exp([0 1 p p+1] * lr) - 1));
bl = n/FS * (700*(exp(m)-1))
exp([0 1 p p+1])의 0에서 31은 32의 길이를 갖습니다. 30+2이죠?
위 식은 n/FS를 제외하면 (2)식에 1125를 뺀것과 같습니다.
그럼 어째서 n/FS를 하느냐. 영문사이트 및 위에서 보는 그래프에 따르면 aplitude가 0~1로 표현되어 있습니다. 이와 같은 스케일로 표현하기 위해서 취해주었습니다.
실제로 bl의 결과가 0~256까지의 값이 나옵니다. 자연수로 해서 1단위로 보면 257의 길이를 갖습니다.
앞서 STFT에서 주파수 영역(0~8000)이 257개로 나뉜것과 같습니다.(STFT의 1+R/2=1+(2^9)/2과 같습니다.)
실제로 계산해보면 n*f/FS이기 때문에 (2^9)*(1/2)=256이 됩니다.
0 1 p p+1은 각각 용도가 있어서 넣은 값입니다.
b1 = floor(bl(1)) + 1;
b2 = ceil(bl(2));
b3 = floor(bl(3));
b4 = min(fn2, ceil(bl(4))) - 1;
bl(1)~bl(4)은 0 1 p p+1의 결과값입니다.
b1=1, b2=2, b3=234, b4=255가 됩니다.
----------------------------------------------------------------------여기까지 1단계로 봅시다.
pf를 식으로 표현하면 ln(1+ (b1:b4)*FS/(2^9)*1/700)/lr
pf가 가지는 값은 0에서 31 미만입니다.
fp는 버림을 적용함으로 0에서 30까지의 값을 가집니다.
pm은 pf에서 정수부를 제거한 값입니다. 이것이 가지는 의의는 영문 자료의 아래의 식을 구현했다는 것입니다.

이는 0Hz에서 8000Hz까지를 257등분하여 0에서 256까지의 257단계의 자연수 스케일로 표시하고 각 필터(0에서 30)마다 0에서 257까지의 스케일에 대하여 갖는 결과값(Hm, 0에서 1사이)을 갖는다. 이는 3차원 공간에의 자료이다.
Matlab으로 영문자료와 같은 그래프를 출력하려고 할때 그냥 plot(데이터)를 해버리면

이런 결과가 나온다.
실제 3차원으로 보는 필터는 다음과 같다.

X,Z평면으로 보면 다음과 같다.

2차원 plot으로 hold on과 for을 이용하여 출력하면 다음과 같다.

필터를 몇개 제거하여보자.
for i=0:3:30으로 필터를 10개정도 제거하여 보자




필터를 통과한 성분들만 남아있는 것을 알 수 있다.
Mel_FilterBank에 사용된 식이 어떻게 나왔는가, Matlab 코드에서 좌표와 소수점 이하 자료로 나누는 부분 등 다루고 싶은 부분이 많으나 아직 이해가 부족하고 시간이 많이 소모되므로 프로젝트가 끝난 후로 미루도록 하겠다.
 Bluetooth.zip
Bluetooth.zip






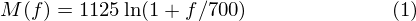
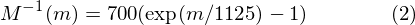
 . Once it is framed we have
. Once it is framed we have  where n ranges over 1-400 (if our frames are 400 samples) and
where n ranges over 1-400 (if our frames are 400 samples) and 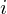 ranges over the number of frames. When we calculate the complex DFT, we get
ranges over the number of frames. When we calculate the complex DFT, we get 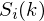 - where the
- where the 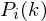 is then the power spectrum of frame
is then the power spectrum of frame 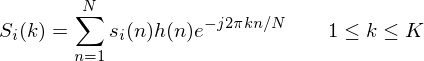
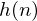 is an
is an 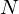 sample long analysis window (e.g. hamming window), and
sample long analysis window (e.g. hamming window), and 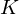 is the length of the DFT. The periodogram-based power spectral estimate for the speech frame
is the length of the DFT. The periodogram-based power spectral estimate for the speech frame 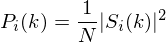
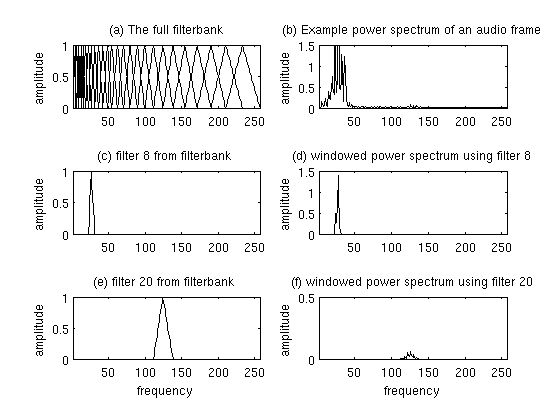
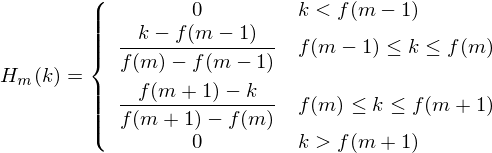
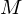 is the number of filters we want, and
is the number of filters we want, and 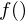 is the list of M+2 Mel-spaced frequencies.
is the list of M+2 Mel-spaced frequencies.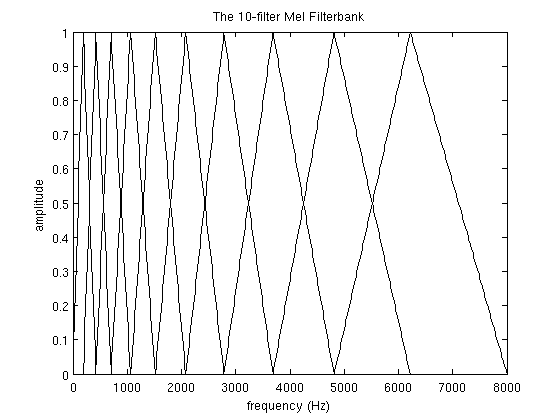
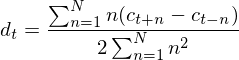
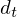 is a delta coefficient, from frame
is a delta coefficient, from frame  computed in terms of the static coefficients
computed in terms of the static coefficients 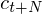 to
to 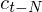 . A typical value for
. A typical value for 